
¿Qué es Pandas? - Analiza tus datos con Pandas en Python parte 1

Pandas es una potente librería de código abierto para Python, la cual nos permite manipular diversos tipos de datos estructurados, incluyendo funciones para leer y escribir datos en varios formatos, como Excel, CSV y más. Por lo mismo es muy utilizada en la ciencia de datos (Data Science)
Una de sus principales características son los DataFrame, los cuales son muy similares a las hojas de Excel, pero permiten utilizar Python para manipularlos, lo que da mayor flexibilidad en la manipulación de datos, abre más posibilidades manipulación y permite la manipulación de un volumen de datos mucho mayor que en hojas de cálculo.
Para utilizarla, debemos importarla de la siguiente manera. Esto es similar a cuando en un computador instalamos un programa.
# importa la libreria Pandas, para utilizarla deberas invocarla usando "pd"
import pandas as pd¿Qué es una librería de Python?
Las librerías de Python son conjuntos de funciones y métodos que permiten realizar muchas acciones sin necesidad de escribir código desde cero. Básicamente tomas prestado el código que hizo otra persona para algún caso especifico.
Una de estas librerías es Pandas, la cual se utiliza para el análisis y manipulación de datos.
¿Qué es un DataFrame? ¿Cuál es su estructura?
# crea una variable llamada "data" desde un Excel que está en Google Drive
data = pd.read_excel("https://docs.google.com/uc?export=download&id=1bqVTtpAF50QSlrtB6DjfeHx1w9UKT7O3")
# visualiza el dataFrame
data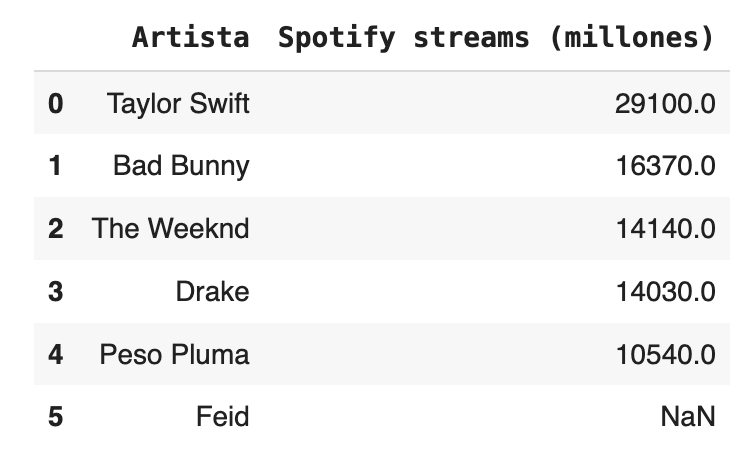
La imagen muestra un DataFrame, que es una estructura de datos bidimensional, similar a una tabla de Excel. Sus elementos son:
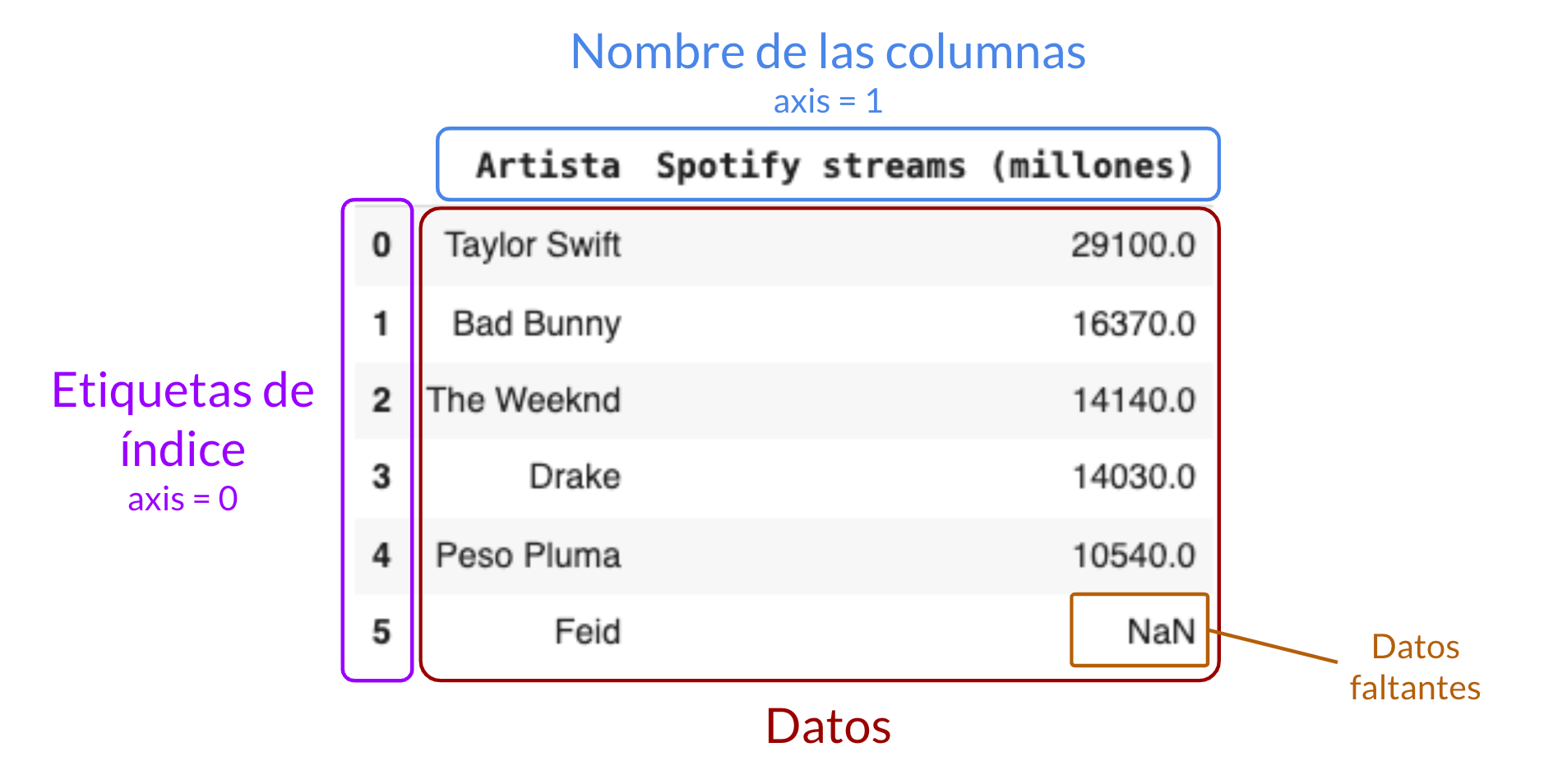
- Nombre de las columnas (axis=1): Encima del DataFrame se muestra el nombre de las columnas, que son "Artista" y "Spotify streams (millones)". Las columnas representan diferentes variables y cada una contiene datos de su respectiva categoría. La etiqueta 'axis=1' se refiere a la orientación horizontal de las columnas en el DataFrame.
- Etiquetas de índice (axis=0): A la izquierda del DataFrame hay una columna adicional sin nombre que muestra las etiquetas de índice, que van desde 0 hasta 5. Estas son básicamente posiciones o identificadores únicos para cada fila de datos. La etiqueta 'axis=0' se refiere a la orientación vertical de las filas en el DataFrame. Si bien en esta imagen son números, estos valores pueden tomar otros tipos de datos, siempre y cuando sean identificadores únicos de cada fila.
- Datos: En el centro del DataFrame se encuentran los datos. Cada fila representa un conjunto de datos correspondientes a un artista y sus streams en Spotify expresados en millones.
- Datos faltantes (NaN): En la última fila de la columna "Spotify streams (millones)", hay un valor "NaN". Este es un acrónimo de "Not a Number" y es utilizado en Pandas para indicar datos que faltan o que son indefinidos.
Creando un DataFrame
Los DataFrame pueden ser creados de varias formas distintas
Creación manual
Puedes indicarle los datos que necesitas manualmente, por ejemplo:
# Para crearlo manualmente debes indicar el nombre de las columnas, datos, y opcionalmente los identificadores de cada set de datos
df_manual = pd.DataFrame(columns = ["Control 1", "Control 2", "Control 3"],
index = ["Michael Scott", "Dwight Schrute", "Jim Halpert"],
data = [[4.0, 3.5, 5.5], [5.4, 5.5, 7.0], [6.6, 6.9, 7.0]])
df_manual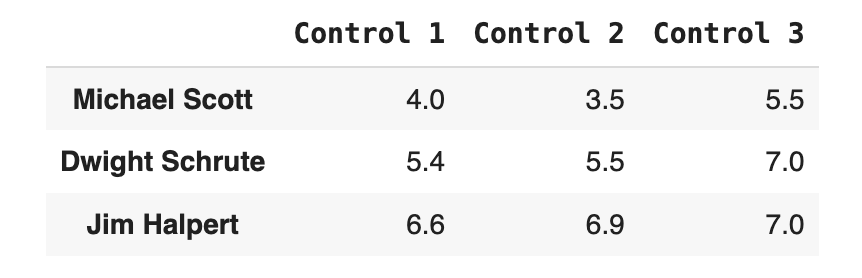
Creando un DataFrame a partir un archivo
También se pueden crear DataFrame a partir de archivos que contengan datos estructurados, como Excel, CSV u otros.
En particular ahora usaremos un archivo de Excel que está en Google Drive. Ten presente que también puedes subirlo a Colab directamente.
df_excel = pd.read_excel("https://docs.google.com/uc?export=download&id=1RjyFp3seXXSwjJMVwT6FBs3lNniDxsNN")
df_excel
Si el archivo tiene muchas hojas, y/o quieres añadir las filas como indices, puedes hacerlo en la misma función
df_excel = pd.read_excel("https://docs.google.com/uc?export=download&id=1RjyFp3seXXSwjJMVwT6FBs3lNniDxsNN",
sheet_name = "productos",
index_col = "ID_Producto")
df_excelInformación sobre el DataFrame
Puedes obtener información sobre el DataFrame, tales como sus columnas, y dimensiones (cuantas filas, y cuantas columnas) tiene.
df_excel.shape # Tiene 30 filas y 3 columnasdf_excel.columnsdf_excel.dtypes # Con dtypes puedes acceder a los tipos de tu DataFrameTambién puedes usarlo en columnas especificas
df_excel.Precio.dtypes
df_excel["Precio"].dtypes # Equivalente Accediendo al DataFrame
Accediendo a una columna
Puedes llamar rápidamente los datos de una columna usando df['Nombre de la columna'] o df.NombreColumna
df_excel["Cantidad"]
df_excel.CantidadAccediendo a varias columnas
También puedes llamar a varias columnas usando la siguiente estructuradf[lista con nombre de las columnas]
df_excel[["Producto", "Cantidad"]] # Notese que es una lista dentro del método para llamar las columnasAccediendo a las filas
Puedes encontrar las filas usando loc y como argumento el indice. Si el indice es un texto, debes especificarlo como tal.
df_excel.loc["SKU26"]Accediendo a varias filas
Si quieres seleccionar todas las filas que esten continuas unas a las otras puedas usar esta estructura
df_excel.iloc[0:2]Nota
Si es esta es la primera vez que te encuentras con algo como 0:2 a eso se le llama slicing, y no ex exclusivo de Pandas.
Es una convención que permite obtener una parte de una lista y se hace con esta estructura inicio:fin donde inicio y fin son índices.
La primera parte, antes del :, significa el indice desde el cual comienza, y la segunda parte hasta donde llega.
Si no hay nada en la primera parte significa que parte desde el primer indice, y si no hay nada en la segunda parte significa que llega hasta el último índice.
También se pueden usar números negativos para hacer la acción en reversa.
Algunos ejemplos:
0:2seleccionaría desde la posición 0 hasta la posición 2, excluyéndola.2:5seleccionaría desde la posición 2 hasta la posición 5, excluyendo la posición 5.-2:seleccionaría desde la posición 2 pero desde el final hacia el inicio, hasta la última posición disponible.2:seleccionaría desde la posición 2 hasta la última posición disponible.
Si quieres acceder a filas especificas, puedes entregar como parametro una lista de las filas
df_excel.iloc[[0, 4, 7]]Si el DataFrame tiene indice, también puedes entregarle una lista de indices en los parámetros de loc
df_excel.loc[["SKU97", "SKU154"]]Accediendo a un set especifico de filas y columnas
Puedes especificar una lista de filas, seguido por una lista de Columnas, y así obtener un conjunto muy especifico de datos
df_excel.iloc[[0, 4, 7], [1, 2]]Si quieres llamar a las columnas por su nombre, puedes usar una estructura como esta
df_excel[["Precio", "Cantidad"]].iloc[[0, 4, 7]]Accede a nuestro curso
Este artículo es parte de nuestro curso sobre Pandas. Revisa el curso completo e inscríbete aquí.
Continua con la siguiente parte de estas guías: Manipulando DataFrames