
Manipulando DataFrames - Analiza tus datos con Pandas en Python parte 2

Ahora que sabemos como cargar nuestros archivos, es hora de usarlos. Comencemos configurando nuestro DataFrame inicial.
import pandas as pd
df_excel = pd.read_excel("https://docs.google.com/uc?export=download&id=1RjyFp3seXXSwjJMVwT6FBs3lNniDxsNN", index_col="ID_Producto")Despliega los primeros o últimos datos
Para mostrar una parte del DataFrame usarás el método head(n) o tail(n), donde 'n' son los primeros o últimos n datos.
df_excel.head(5) # muestra los primeros 5 datosdf_excel.tail(5 # muestra los últimos 5 datosMuestra un resumen de los datos
Con describe() puedes obtener rápidamente algunas estadísticas descriptivas sobre tus datos
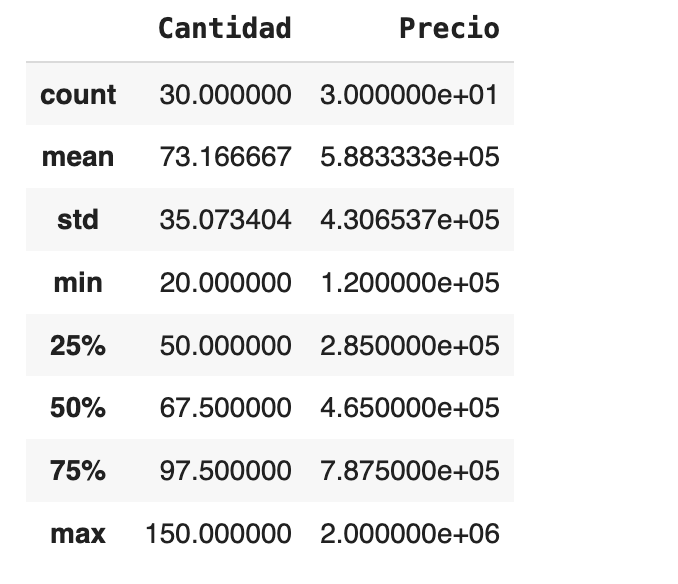
Más funciones de estadistica descriptiva
# Promedio
df_excel.Precio.mean()
# Tambien funciona asi:
df_excel["Precio"].mean()# Minimo
df_excel.Precio.min()
# Tambien funciona asi:
df_excel["Precio"].min()# Maximo
df_excel.Precio.max()
# Tambien funciona asi:
df_excel["Precio"].max()# Sumatoria
df_excel.Cantidad.sum()
# Tambien funciona asi:
df_excel["Cantidad"].sum()# Contar por tipo
df_excel.Producto.value_counts()
# Tambien funciona asi:
df_excel["Producto"].value_counts()# Contar total columna
df_excel.Producto.count()
# Tambien funciona asi:
df_excel["Producto"].count()Filtra DataFrames
Puedes seleccionar un set de datos que cumplen una condición utilizando esta estructura df[condicion]. Por ejemplo
df_excel[df_excel["Cantidad"] > 100]Estas condiciones pueden ser complejas a través de usar indicadores &(AND) y | (OR)
# Tienen que cumplirse dos condiciones al mismo tiempo
df_excel[(df_excel["Cantidad"] > 100) & (df_excel["Precio"] < 200000)]# Tiene que cumplirse al menos una condición
df_excel[(df_excel["Cantidad"] > 100) | (df_excel["Precio"] < 200000)]Para filtrar por aquellos que contienen un texto determinado, puedes usar .str.contains(). Nótese que es sensible a mayúsculas y tildes.
# Filtra los productos que contienen la palabra "Cámara"
df_excel[(df_excel["Producto"].str.contains("Cámara"))]Ordena DataFrames
Para ordenar los datos en tu DataFrame puedes usar la siguiente estructuradf.sort_values(by=nombre_columna, ascending=True/False)
El argumento ascending es True cuando los datos van de menor a mayor, y es False en el caso contrario.
Puedes combinarlo con el método head() y así desplegar un top 5, top 10, o similar. Por ejemplo así puedes ver el top 5 productos por precio.
df_excel.sort_values(by="Precio", ascending=False).head(5)Gestión de datos vacios
Un problema común la hora de gestionar datos es que hay columnas que no tienen todos los datos. Miremos este ejemplo:
df_artistas = pd.read_excel("https://docs.google.com/uc?export=download&id=1bqVTtpAF50QSlrtB6DjfeHx1w9UKT7O3")
df_artistas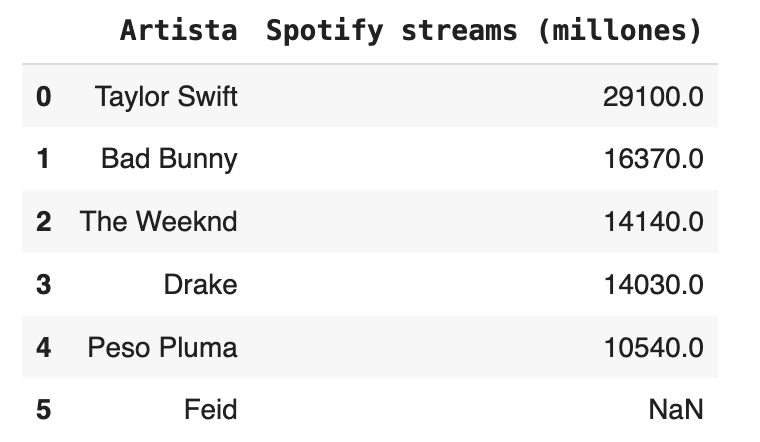
Identificando datos vacios
En un DataFrame pequeño, como el que acabamos de crear, es fácil ver donde y cuántos NaN hay. Pero cuando manipulamos grandes volúmenes de datos es mejor llamar el siguiente tipo de código para obtener un resumen de este problema.
df_artistas.isna().sum()
"""
Output:
Artista 0
Spotify streams (millones) 1
dtype: int64
"""Puedes ver que en la columna Spotify streams (millones) tenemos 1 dato con NaN, mientras que en las otras columnas no tenemos.
Eliminando datos vacíos
La fila de Feid no tiene ningún dato, por lo que podría ser recomendable sacarlo del DataFrame, así podemos manipular los otros datos.
df_artistas_filtrado = df_artistas.dropna()
df_artistas_filtradoAdvertencia: el método dropna() elimina toda la fila si es que alguna columna es NaN.
Nota: Tienes que crear otro DataFrame con la información filtrada. Esto es una protección para evitar que elimines fácilmente los datos.
Llenando datos vacios
Otra manera de gestionar estos datos es llenando el vacio que dejó. Vamos a reemplazar el NaN en este caso por 7900, que fue el número asociado a Feid para este año, usando fillna
df_artistas_llenado = df_artistas.fillna(7900)
df_artistas_llenadoSi queremos ser super específicos con como vamos a completar los datos, vamos a usar el método loc para específicamente localizar ese dato.
df_artistas.loc[5, "Spotify streams (millones)"] = 7900
df_artistasCreando una columna usando una formula
Puede añadir una nueva columna en base a cálculos.
En el siguiente ejemplo tenemos un DataFrame con la cantidad y precio de cada producto.
df_excel.head(3)
Suponga que quiere saber cuáles son los productos que representan más valor en su inventario. Para ello le pide que cree una nueva columna llamada "ValorInventario" que contenga el valor de la cantidad multiplicada por el precio de cada producto.
# Generamos la columna
df_excel["ValorInventario"] = df_excel.Cantidad * df_excel.Precio
# Desplegamos el cambio, con solo los 3 primeros productos
df_excel.head(3)Borrando una columna
Para borrar una columna debe usar drop, y especificar axis=1, que es el indicador de columnas. En pandas axis=0 referencia a las filas.
df_productos_borrado = df_excel.drop("ValorInventario", axis=1)
# Desplegamos el cambio, con solo los 3 primeros productos
df_productos_borrado.head(3)Nota: Tienes que crear otro DataFrame con la información borrada. Esto es una protección para evitar que elimines fácilmente los datos y no puedas recuperarlos.
Accede a nuestro curso
Este artículo es parte de nuestro curso sobre Pandas. Revisa el curso completo e inscríbete aquí.
Continua con la siguiente parte de estas guías: Graficar y Exportar Datos