
Lo que necesitas saber para mitigar sesgos en un algoritmo
¿Sabías que los algoritmos pueden tener sesgos que están afectando sus decisiones? En este post, te enseñamos cómo mitigarlos con conceptos y herramientas para que lo apliques en cada etapa de desarrollo. ¡Aprende a crear algoritmos más justos y éticos!

por Jonathan Vásquez | linkedin | gscholar
En este artículo previo conversamos sobre cómo las Inteligencias Artificiales pueden presentar sesgos en sus respuestas. Al existir el riesgo que estos potencialmente lleven a efectos discriminatorios, es crucial tomar medidas para mitigarlos, en especial en tiempos como hoy, donde están apareciendo muchas tecnologías de uso diario que incorporar inteligencia artificial como ChatGPT, Midjourney, Jasper, y muchas más, pero ¿Qué enfoques existen para abordar este problema? ¿Dónde se mitigan los sesgos? ¿Existen librerías o herramientas específicas para este objetivo?
Primero, hablemos del poceso de desarrollo de una máquina de aprendizaje, un elemento crucial en una Inteligencia Artificial, el cual puede ser dividido a grandes rasgos en tres macro-etapas secuenciales:
- Primero, se colectan y generan los datos. Antes que estos sean utilizados en el entrenamiento, los datos son limpiados de ruidos, se aplica tratamiento a datos faltantes/vacíos, y se transforman en un formato apto para la máquina de aprendizaje. Aplicar mitigación en esta etapa de desarrollo se conoce como enfoque pre-processing.
- Luego, se entrena y desarrolla el modelo, el cual recibirá las entradas y entregará un valor de vuelta. En otras palabras, “procesamos” el algoritmo que usaremos para automatizar alguna tarea (clasificación, regresión, agrupamiento, entre otras). Entre otras actividades, aquí se evalúan la técnica de aprendizaje y se identifica el conjunto de hiperparámetros que maximiza el desempeño del modelo. Si adicionalmente consideramos técnicas que agregan criterios al proceso de aprendizaje para minimizar la disparidad de la salida del modelo, estas son consideradas como enfoques in-processing.
- Finalmente, los resultados del algoritmo son utilizados para tomar decisiones. Algunas de estas pueden ser automáticas (sin intervención adicional) o son consideradas como un input para que alguien tome una decisión final, pudiendo considerar (o no) lo entregado por el modelo. Post-processing son los enfoques aplicados en esta etapa del pipeline para modificar la salida del modelo de tal forma que se cumplan ciertas medidas de paridad.
Estos tres enfoques nos ayudan a contestar las primeras dos preguntas: ¿Qué enfoques existen? y ¿dónde se mitigan los sesgos? . En corto lo clave está en saber que solo nos bastaría con identificar si el enfoque de mitigación es aplicado antes, durante, o después de que el algoritmo de aprendizaje es "procesado".
¡Listo! Ya tenemos el marco necesario para ahora describir algunas herramientas útiles que puedes considerar en tu machine learning pipeline y así responder a nuestra tercera pregunta: ¿Existen librerías o herramientas específicas para este objetivo?
Pre-processing
El objetivo de estos enfoques es remover el sesgo presente en los datos antes que sean utilizados en el entrenamiento. Los datos son transformados de tal manera que no reflejan signos del sesgo o patrones discriminatorios. Generalmente, esto se realiza definiendo primero el o los atributos sensibles (también conocidos como atributos protegidos), tales como género, raza, o edad, la cual es totalmente dependiente del contexto.
Estos también nos ayudarán a identificar a qué grupo pertenece cada individuo y evaluar posteriormente si el algoritmo está sugiriendo decisiones discriminatorias. Una vez definido el o los atributos sensibles, se aplican las técnicas pre-processing. Algunas de ellas son:
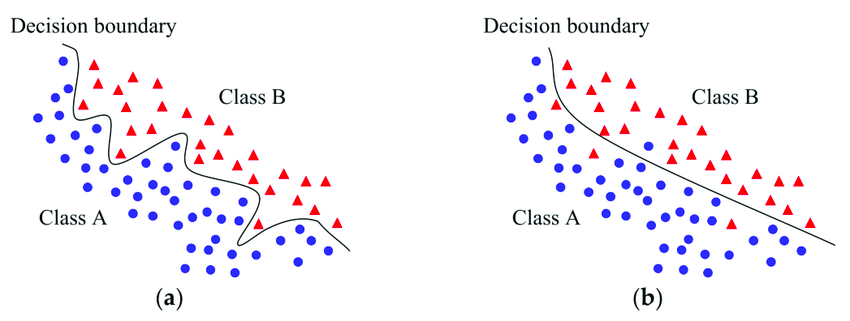
- Sampling: como su nombre lo indica, se realiza un muestreo de la base de datos. Por ejemplo, Kamiran y Calders proponen hacer un Preferential Sampling (PS), donde datos cercanos al decision boundary (zona o espacio donde el modelo cambia de decisión en la clasificación) tienen mayor probabilidad de ser duplicados o evitados en el muestro final. Intuitivamente, mientras más cercana al decision boundary, aumenta aumenta la probabilidad de que la salida del modelo no sea la correcta, por tanto, la persona representada por ese dato tiene más probabilidad de ser discriminada o favorecida. La preferencia en el muestro se hace en base a la pertenencia al grupo demográfico y del lado en que se ubica en el decision boundary. Por ejemplo, en un caso de entregar préstamo o no y con dos grupos demográficos en base a la raza (raza verde y amarilla, con la verde como el grupo minoritario) las observaciones verde-otorgado y amarilla-no otorgado son preferidas en el muestreo.
- Reweighing: los mismos autores de PS plantean una lógica similar al sampling, sin embargo, en vez de obtener un muestro, se genera un peso que luego es considerado en el entrenamiento. Similar al muestreo, las observaciones del grupo desventajado son asignados con mayores pesos. El problema que puede surgir es que no todos los modelos puedo considerar pesos en sus procesamientos. Una implementación de este enfoque puede ser encontrado en la librearía AIF360, desarrollada por IBM.
- Fair Representation: un enfoque mucho más avanzado y preferido actualmente es el de generar una representación de los datos en la que se codifica la base con tal de minimizar la información respecto al atributo sensible y su relación con los otros atributos. De esta manera, podemos tener una base de datos de individuos postulando a créditos, pero existe una alta correlación entre el género de la persona y otros atributos (por ejemplo: sueldo y relación marital). Usando un enfoque de Fair Representation, podríamos generar una base codificada en donde tal correlación es minimizada. Ejemplos de este enfoques son el CorrelationRemover de Fairlearn, el LFR de AIF360, y el reciente método FBC de Gitiaux y Rangwala (repo).
In-processing
El segundo grupo de técnicas se enfoca en modificar los algoritmos de machine learning para agregar condiciones durante el proceso de entrenamiento. Cuando un algoritmo es entrenado, generalmente se definen objetivos que buscan maximizar el desempeño en alguna tarea. Bajo un enfoque in-processing, el objetivo puede ser modificado, considerando elementos de paridad, o bien limitado por medio de condiciones de paridad.
- Regularization: durante el entrenamento los modelos buscan minimizar la función de pérdida (o function loss en inglés), la que mide el error del modelo. Esta función puede incluir también otros elementos que regulan la medición del error, el cual se raliza por medio de regularizer terms. Por ejemplo, Kamishima et al propone agregar a la función de perdida un penalizador que mide la dependencia entre el atributo sensible y la salida del modelo. De esta manera, se estaría buscando un outcomes lo más cercano al real y también lo menos correlacionado o dependiente del atributo sensible. En general, estos tipos de enfoquen establecen un trade-off entre el despempeño y el criterio de paridad, el cual se establece por pesos que se asigna a cada elemento.
- Constraints: un enfoque similar es por medio de restricciones a las funciones objetivos. Aunque posteriormente son agregadas a la función de pérdida por medio de ejercicios matemáticos (por ejemplo, por medio del Lagrange multipliers), su formulamiento es distinto. Por ejemplo, se podría establecer una banda de diferencia existente entre los errores que el modelo muestra en distintos grupos. De esta manera, se busca una paridad en el error que el modelo muestra en los distintos grupos. Ejemplos aplicados pueden ser encontrados en la libreria Fairlearn, entre ellos el método Bounded Group Loss.
- Adversarial: estos enfoques modifican el entrenamiento por medio del uso de técnicas de adversarial learning, en donde dos modelos son entrenados. El primero recibe las observaciones y entrega una estimación de la variable objetivo, mientras que el segundo recibe la salida del primero y predice el atributo sensible. Las funciones de pérdidas se definen de tal manera que el segundo modelo buscará predicir lo mejor posible el atributo sensible, y el primero buscará generar predicciones precisas pero que a la vez compliquen la tarea de predicción del segundo. Aplicaciones de estos enfoques se pueden encontrar en el Adversarial Package de Fairlearn y el Adversarial Debiasing the AIF360.
Post-processing
Finalmente, el tercer grupo trabaja sobre las salidas de los modelos. Básicamente, se propone ajustar lo entregado por el modelo de tal manera que se mantenga el desempeño del modelo pero que a la vez se cumplan ciertos criterios de paridad. Algunos ejemplos son:
- Calibration: el objetivo de estos enfoques es modificar la salida del modelo. Esto se puede realizar por medio de una calibración o cambiando la predicción del modelo. Por ejemplo, Pleiss et al y Hardt et al proponen enfoques en donde el umbral de clasificación de los modelos son calibrados para los distintos grupos, maximizando el desempeño y minimizando la disparidad. Aplicaciones de estos enfoques pueden ser encontrado en los siguientes links: Calibration Equalized Odds y Threshold Optimizer
- Auditor: otro enfoque sería ayudar al usuario con información adicional sobre el riesgo de discriminación al usar la salida entregada por el modelo. Bajo este enfoque, Gitiaux y Rangwala proponen un auditor que evalúa si para un individuo existe riesgo de ser discriminado por un algoritmo dado (repo). Reject Option Classifier identifica para qué observaciones existe una certeza por parte del modelo baja, proponiendo rechazar tales predicciones.
¡Hemos respondido a todas las preguntas! 🎉
¡Felicitaciones, has adquirido nuevos conocimientos sobre como mitigar los sesgos en tus modelos! Ten en cuenta que estos son solo algunos de los enfoques que puedes encontrar en la litaretura e industria.
Además, el campo crece rápidamente y todos los días son publicadas técnicas novedosas. Por otro lado, esto son solo enfoques cuantitativos; hablaremos de los enfoques cualitativos en otro post, así que te invito a suscribirte y estar a atento para futuras publicaciones.
Coméntanos más abajo si tienes alguna duda o deseas que hablemos de algún tema en particular. ¡Nos vemos en un siguiente post!
Referencias Relevantes:
- Microsoft (2020). Fairlearn: A toolkit for assessing and improving fairness in AI. Technical Report. MSR-TR-2020-32.
- IBM (2018). AI Fairness 360: An extensible toolkit for detecting,
understanding, and mitigating unwanted algorithmic bias. - Pessach, D., & Shmueli, E. (2022). A review on fairness in machine learning. ACM Computing Surveys (CSUR), 55(3), 1-44.