
ChatGPT supera al 99% de los estudiantes en la PAES
¿Qué tan bien puede responder GPT al PAES? Descubre cómo la inteligencia artificial supera a los postulantes en las pruebas de acceso a la educación superior.

escrito por Jonathan Vásquez | linkedin | gscholar
El Expresidente del Banco Central de Chile y actual Decano de la Facultad de Economía y Negocios de la Universidad de Chile, José De Gregorio, puso a prueba al ChatGPT con tres preguntas de economía y concluyó que “pasa apenas”. Así que en EvoAcademy quisimos replicar el experimento y desafiamos a ChatGPT a resolver las Pruebas de Acceso a la Educación Superior (PAES) de Chile.
¡Los resultados nos dejaron boquiabiertos! ChatGPT logra alcanzar hasta 960 puntos PAES. Asímismo, la versión gratuita de ChatGPT, que usa el modelo GPT3.5, acertó más del 75% de las preguntas en cada prueba. Mientras que con el modelo GPT4 (versión de pago), el acierto superó el 93%, llegando a fallar en una sola pregunta en una de las pruebas que le propusimos.
Además, encontramos diferencias de casi 200 puntos de puntajes PAES entre la versión gratuita y pagada de ChatGPT, y estimamos que logra estar dentro del 1% de puntajes más altos de postulantes que rindieron la prueba de Comprensión Lectora el 29 noviembre del 2022 (que se rindió en Chile un día antes del lanzamiento de ChatGPT).
Te invitamos a reflexionar sobre las implicancias éticas, sociales y educativas de este fenómeno. ¿Te atreves a conocer los resultados de ChatGPT respondiendo la PAES y que supera a la mayoría de los postulantes? Sigue leyendo y sorpréndete.
Para realizar este experimento, utilizamos las pruebas oficiales publicadas por el Departamento de Evaluación, Medición y Registro Educacional (DEMRE) para el proceso de Admisión 2023. También descargamos las pruebas modelos que la misma institución deja a disposición de los postulantes a inicios de cada año del proceso. Cada prueba consta de 65 preguntas de selección múltiple (excepto Ciencias y Matemáticas M2, que tienen 80 y 55, respectivamente) donde solo una es la correcta.
Para este experimento consideramos las pruebas de Comprensión Lectora y la de Historia y Ciencias Sociales. Las otras contenían gran cantidad de imágenes y requerían un procesamiento adicional, por tanto serán analizadas en un futuro post. ¡Así que suscríbite aquí para recibir una notificación cuando lo publiquemos!
Primero, transformamos todas las pruebas que estaban en formato PDF a un archivo de texto plano. Esto facilita el procesamiento y automatización de los experimentos. Estos archivos son los que usamos para entregarle las preguntas y alternativas a ChatGPT.
Para cada prueba configuramos el comportamiento general de ChatGPT de tal forma que esperara recibir una lista de preguntas de alguna temática y tuviera que entregar de vuelta una tabla con dos columnas, una con el número de la pregunta y otra con la letra de la alternativa que considerara correcta. El prompt que indica este contexto fue el siguiente:
Responde a las siguientes preguntas extraídas de la [PRUEBA] del Ministerio de Educación de Chile. Entrega una columna con el numero de la pregunta seguida de la letra de la alternativa correcta.
Donde [PRUEBA] la reemplazamos con la prueba que queremos que responda (por ejemplo: Prueba de Acceso a la Educación Superior (PAES) de Historia y Ciencias Sociales). Posteriormente le entregamos los enunciados y alternativas de las preguntas, esperando que ChatGPT nos entregara de vuelta las respuestas.
En los experimentos usamos dos modelos disponibles en ChatGPT: GPT3.5 y GPT4. El primero es el que usa la versión gratuita de ChatGPT, mientras que para acceder al segundo necesitamos pagar el Plan Plus. GPT4 es una versión mejorada y actualizada de GPT3.5, y fue lanzado el 14 de Marzo del 2023, un poco más de 4 meses después que se lanzó ChatGPT.
Para evaluar el desempeño, comparamos las respuestas de ChatGPT con las claves oficiales que el DEMRE publica junto con las pruebas. Calculamos el porcentaje de acierto por prueba y también el puntaje PAES que obtendrían según la tabla y las indicaciones entregadas por el DEMRE en el instructivo.
En pro de la transparencia y replicabilidad, pronto publicaremos el repositorio con todo el código y un post explicando en detalle cada paso. Así que aquí tienes una segunda motivación para suscribirte.
Suscríbete a nuestras novedades aquí.
Resultados
Según los resultados, GPT4 sobresale en todas las métricas. Primero, calculamos un promedio de todas las pruebas con el objetivo de evaluar a nivel general el desempeño de ChatGPT respondiendo pruebas PAES. Segun la Tabla 1, GPT3.5 obtuvo un acierto promedio del 80.00% y GPT4 del 94.62%, una diferencia de más de 14 puntos porcentuales. En términos de preguntas correctas promedio, también GPT4 muestra mucho mejor rendimiento, respondiendo correctamente un total de 61.5 preguntas en promedio de las 65 que tiene en total cada prueba. Esta es una diferencia de casi 10 correctas más en promedio que su par GPT3.5 (el modelo gratuito).
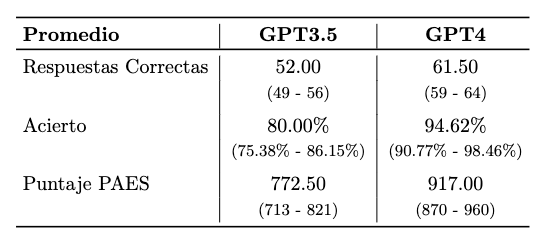
Segundo, evaluamos el desempeño de la Inteligencia Artificial por tema, donde las diferencias más significativas se observan en la prueba de Comprensión Lectora. Los resultados se pueden ver en la Figura 1. Según la figura, GPT3.5 mostró un acierto promedio del 83.59% en Historia y Ciencias Sociales, y 76.41% en Comprensión Lectora. Por su parte, GPT4 mostró desempeños similares en ambas pruebas: 94.36% y 94.87% respectivamente, una diferencia de hasta +18.46 puntos porcentuales con su par GPT3.5. La diferencia mayor la observamos en la Prueba Modelo de Comprensión Lectora, en donde GPT4 responde correctamente 13 preguntas más que su par, reflejando una diferencia de 20.00 puntos porcentuales de acierto por sobre GPT3.5.
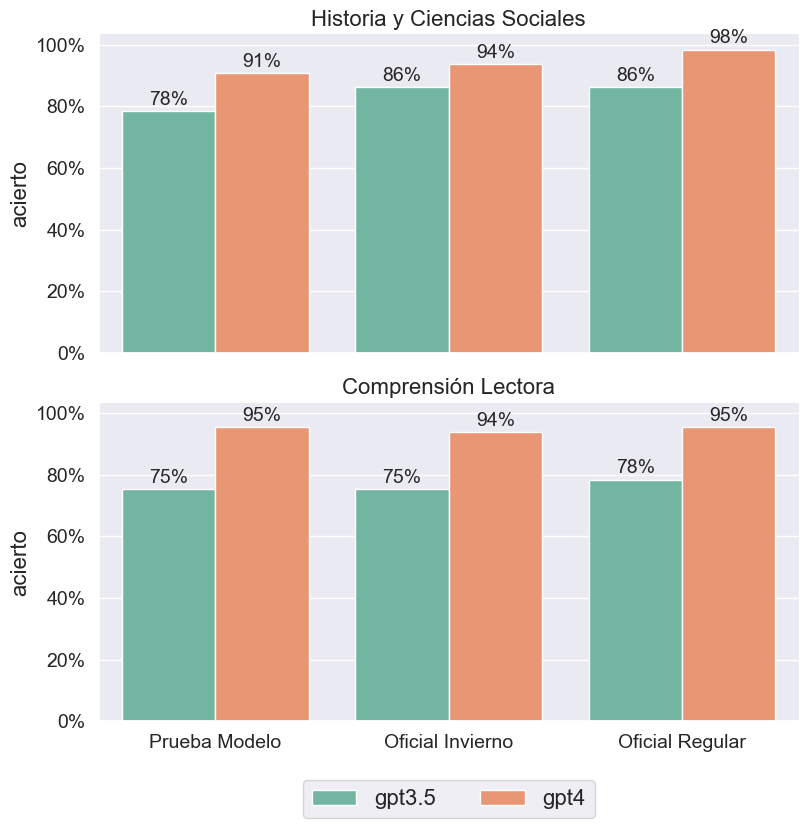
Luego, hicimos la misma evaluación considerando los puntajes PAES que obtendría ChatGPT. De acuerdo al instructivo del DEMRE, 5 de las 65 preguntas "corresponden a preguntas piloto y no se consideran para el cálculo del puntaje". Por tanto, para simular el puntaje final, contamos la cantidad de respuestas correctas sin considerar aquellas que son pilotos. En consecuencia, de acuerdo a la Tabla 1, GPT4 muestra un promedio de 917 puntos en las pruebas rendidas, un poco más de 144 por sobre el promedio mostrado por GPT3.5. También hicimos el análisis pero a nivel de tipo de prueba, cuyos resultados se muestran en la Figura 2. De acuerdo a esta, GPT4 obtiene hasta casi 200 puntos más que su par en las pruebas oficiales que rindieron postulantes en Julio y Noviembre del 2022.
También analizamos las diferencias a nivel de temática, donde GPT4 obtuvo en promedio de 914.33 puntos en Historia y Ciencias Sociales, y 919.67 en Comprensión Lectora. Sus puntajes más altos fueron en la prueba oficial regular, rendida por los postulantes el 28 y 30 de noviembre del 2022, donde obtuvo 955 y 960 puntos respectivamente. Por otro lado, su par gratuito mostró rendimientos por debajo del umbral de los 900 puntos, siendo el más alto de 827 puntos (en Historia y Ciencias Sociales) y el más bajo de 747 (en Comprensión Lectora).
En comparación con la distribución de postulantes que rindieron la prueba en noviembre del 2022, ambos modelos se alejan de los desempeños promedios. De acuerdo al informe técnico del DEMRE, en la prueba de Historia y Ciencias Sociales, los postulantes de la generación que egresó el 2022 obtuvo un promedio de 492.3 puntos, en comparación a los 536 que mostraron las generaciones anteriores; GPT3.5 y GPT4 obtuvieron 821 y 955 respectivamente, una diferencia de hasta 455.7 puntos con los postulantes.
Similares hallazgos se observan al comparar puntajes en la prueba Comprensión Lectora, aunque con menor diferencia. La generación 2022 obtuvo un puntaje promedio de 631.9 puntos, y las generaciones previas de 670.8; mientras que GPT3.5 y GPT4 alcanzaron 761 y 960 puntos respectivamente.
Además, usando la herramienta WebPlotDigitizer, extrajimos densidades estimadas de las distribuciones de puntajes PAES reportados en gráficos por DEMRE en el informe técnico. Con esta información pudimos estimar que ChatGPT hubiese estado dentro del 2% superior de quienes rindieron la prueba de Historia y Ciencias Sociales, mientras que en Comprensión Lectora y con GPT3.5 habría estado dentro del 23% de más altos puntajes y dentro del 1% con GPT4.
Finalmente, motivados por Kizilcec y Lee, quienes plantean que cuando se trata de innovación en la educación debemos asegurarnos que estas generen un Closing Gap (es decir, que beneficie a todas las personas y que además reduzca las brechas entre grupos) hicimos el mismo ejercicio pero considerando los tipos de colegios
Los resultados muestran una marcada brecha entre colegios con mayores y menos recursos. En Historia y Ciencias Sociales, postulantes de colegios particulares pagados obtuvieron un puntaje promedio de 613.2 puntos, los de particulares subvencionados 499.2, y los de colegios municipales y servicios locales 473.4 puntos. Comparándolos solamente con el puntaje más bajo de los modelos (GPT3.5 con 821 puntos), las diferencias llegan a ser de aproximadamente 347 puntos.
Por otro lado, en Comprensión Lectora, los promedios fueron de 748.9 puntos para colegios particulares pagados, 641.8 para subvencionados, y 607.7 para municipales y servicios locales. En este caso la diferencia entre el peor puntaje de los modelos (GPT3.5) y el mayor entre tipo de colegios (particulares pagados) es de +12.1. Sin embargo, la diferencia con postulantes de subvencionados y municipales y servicios locales es de más de casi 120 puntos.
Este ejercicio no debe ser considerado como un estudio acabado. Sin embargo, estos resultados preliminares nos invitan a reflexionar y preguntarnos sobre el uso de la IA en la educación.
Una primera pregunta es ¿Qué implicancias tiene esto? Por un lado, vemos un potencial de la inteligencia artificial para apoyar el aprendizaje y la evaluación de los estudiantes. Por ejemplo, estos modelos podrían usarse para generar feedback personalizado, sugerir recursos educativos o crear preguntas adaptativas. Sin embargo, tal como plantean Kizilcec y Lee, debemos asegurarnos que tales innovaciones en educación generen un Closing Gap, y no que repliquen o aumenten las brechas ya presentes en el sistema.
Aunque más estudios son necesarios, ya vimos que GPT4 muestra una diferencia significativa respecto a su par gratuito. Si no pagamos podemos acceder solo al modelo GPT3.5, mientras que acceder a GPT4 tiene un costo. Por tanto, de usarse estos modelos, ¿Cómo nos aseguramos que el costo no sea una barrera significativa que replique, o peor aun, aumente la brechas ya existentes en la sociedad? También, ¿Cómo podemos aprovechar estas tecnologías para diseñar herramientas más justas, inclusivas y pertinentes? ¿Cómo podemos garantizar la seguridad y la ética en el uso de estos sistemas? ¿Cómo podemos preparar a los futuros profesionales para enfrentar un mundo cada vez más digitalizado e interconectado? Estas son algunas de las preguntas que nos motivan a seguir explorando y experimentando con la Inteligencia Artificial.
Queríamos compartir con ustedes nuestros hallazgos e invitarlos reflexionar sobre este tema tan relevante para el desarrollo educativo y social. Por eso, coméntanos qué opinas más abajo y suscríbete para recibir noticias de los futuros experimentos que iremos publicando.
